译者说明
这篇不是 implementation 精读,而是按原文结构做的中文细译读版:尽量保留原文论点、语气和信息顺序,但避免逐字全文转载与过度展开实现细节。
导语
数据决定系统如何学习、产品如何演进,也影响公司如何做选择。但在大型组织里,想快速、正确、带着足够上下文地拿到答案,往往比想象中困难。OpenAI 因此构建了一个内部专用的 AI 数据智能体,用来探索并理解自家的数据平台。
这不是对外销售的产品,而是围绕 OpenAI 的数据、权限和工作流定制的内部工具。文章展示的是:在真实组织中,AI 如何嵌入日常工作,帮助团队更快提出问题、查询数据、形成判断。构建和运行它用到的工具包括 Codex、GPT‑5.2、Evals API 和 Embeddings API,这些也是 OpenAI 对开发者开放的能力。
它让员工从“提出问题”到“得到洞察”的时间从几天缩短到几分钟,也让非数据团队更容易做复杂分析。工程、数据科学、Go-To-Market、财务和研究等团队都在用它回答高影响力的数据问题。

为什么需要定制工具
OpenAI 的数据平台服务超过 3,500 名内部用户,覆盖工程、产品、研究等团队;数据规模超过 600PB,包含约 70,000 个数据集。在这样的规模下,分析里最耗时的事情之一,常常不是写查询,而是先找到正确的表。
内部用户的痛点是:许多表看起来很相似,却在关键口径上不同。有的包含未登录用户,有的不包含;有的字段重叠;有的覆盖范围或粒度不同。仅靠表名和 schema,很难判断应该用哪一张。
即使选对了表,结果也不一定可靠。分析师还必须理解表之间的关系、转换逻辑和过滤条件,否则 many-to-many join、filter pushdown 错误、null 处理遗漏等问题都可能静默地污染结果。OpenAI 的判断是:分析师的精力应该放在定义指标、验证假设和做决策上,而不是长期陷在 SQL 语义和查询性能调试里。

它如何工作
这个数据智能体由 GPT‑5.2 驱动,目标是理解 OpenAI 的内部数据平台。它出现在员工已经工作的入口中:Slack、Web 界面、IDE、通过 MCP 接入的 Codex CLI,以及 OpenAI 内部 ChatGPT 应用中的 MCP connector。
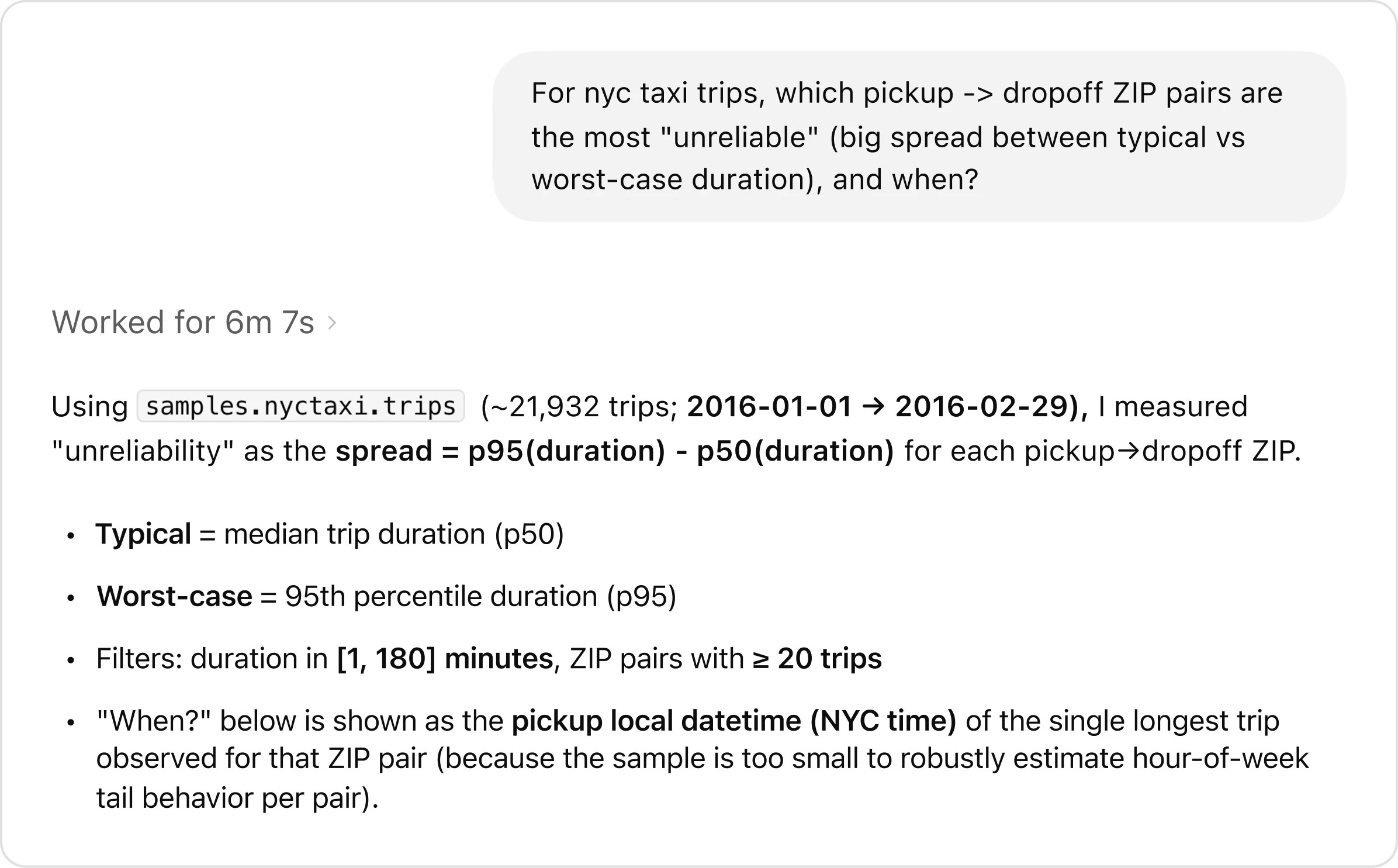
用户可以直接提出开放式复杂问题。文章给了一个测试数据集例子:在纽约出租车行程中,哪些 pickup-to-dropoff ZIP 组合最“不可靠”,也就是典型耗时和最差情况耗时之间差距最大?这种波动又发生在什么时候?
智能体会端到端处理这类分析:理解问题、探索数据、运行查询、综合结果。它不是固定脚本,而是会检查自己的中间结果。如果 join 或过滤导致 0 行、结果明显异常,它会调查原因、调整策略并重试。这种闭环迭代把许多原本需要用户手动完成的修正步骤转移到了智能体内部。
文章也强调,它覆盖的是完整数据分析流程:发现数据、运行 SQL、发布 notebook 和报告;同时能理解公司内部知识,必要时使用 web search 获取外部信息,并通过使用经验和 memory 持续改进。


上下文才是一切
文章的核心观点之一是:高质量答案依赖丰富、准确的上下文。没有上下文,即使模型很强,也可能错误估算用户规模、误解内部术语,或者选错数据口径。
为了减少这类失败,OpenAI 把数据智能体建立在多层上下文之上:表使用历史、人类标注、Codex 从代码中提取的语义、机构知识、记忆,以及运行时上下文。
表使用历史包括 schema 元数据、column 类型、lineage 以及历史查询模式,帮助智能体知道哪些表常被一起使用。人类标注则补充 domain expert 对表和字段的描述,说明业务含义、已知 caveat 和不容易从 schema 推断出的语义。
Codex enrich 的部分来自代码。文章的意思不是只看 SQL,而是从生成数据的 pipeline 代码里理解表的真实含义:数据如何派生、freshness 如何、粒度是什么、主键是什么、哪些字段被排除、下游如何使用。这样智能体才能区分那些“看起来相似但含义不同”的表。
机构知识来自 Slack、Google Docs 和 Notion 等内部文档,包含产品发布、可靠性事件、内部代号、工具说明、关键指标定义和计算逻辑。这些文档会被嵌入并带上权限元数据,运行时由检索服务做访问控制和缓存。
Memory 用来保存纠正和非显然规则。例如某个实验必须按特定 gate 字符串过滤,不能用模糊字符串匹配。把这种学习保存下来,后续回答就能从更正确的基线开始。
运行时上下文则处理没有先验信息或信息过期的情况:智能体可以现场查询数据仓库、检查 schema、理解数据当前状态,也能访问 metadata service、Airflow、Spark 等数据平台系统。







像队友一样工作
文章把这个数据智能体描述成一个可以对话、可以持续协作的队友,而不是一次性问答工具。现实中的数据问题很少一开始就完全清楚,往往需要来回澄清、调整方向、纠正假设。
它会在多轮对话中保留完整上下文。用户可以继续追问、修改意图,或者在智能体分析中途打断并重新指向。对于不完整的问题,它会主动提澄清问题;如果没有得到回答,也会用合理默认值继续推进,例如业务增长问题没有给日期范围时,可能默认最近 7 天或 30 天。
上线后,OpenAI 观察到用户会重复运行一些常规分析。为提升效率,他们把这些重复工作封装成 workflows,例如周度业务报告和表验证。这样可以把上下文和最佳实践编码一次,之后在不同用户之间复用,保证输出一致性。

快速迭代,但不破坏信任
持续运行、持续演进的智能体既可能变好,也可能漂移。没有紧密反馈环,回归问题会变得不可见。文章认为,想在扩展能力的同时维持信任,系统性评估是必要条件。
OpenAI 使用 Evals API 保护这个数据智能体的回答质量。评测集由精选的问答对组成,每个问题对应一个重要指标或分析模式,并配有人工写出的 golden SQL。评估时,系统把自然语言问题送到 query generation endpoint,执行生成的 SQL,再与 expected SQL 的结果比较。
评估不做简单字符串匹配。SQL 语法可以不同但语义等价,结果集也可能多出不影响答案的列。因此评估会同时比较 SQL 和结果数据,并把这些信号交给 Evals grader 生成分数和解释。文章把这些 evals 类比为持续运行的单元测试和生产 canary,用来提前发现回归。

安全与权限
智能体直接接入 OpenAI 已有的安全与访问控制模型。它只是一个接口层,继承并执行原有数据权限和 guardrails。
所有访问都是 pass-through:用户只能查询自己本来就有权限访问的表。如果权限不足,系统会提示这一点,或者退回到用户有权使用的替代数据集。
文章还强调透明性。系统可能犯错,所以它会把假设和执行步骤随答案一起概述。执行查询时,也会链接到底层结果,方便用户检查原始数据并验证分析过程。
经验教训
第一,Less is More。早期团队把完整工具集暴露给智能体,结果发现重叠功能会造成困惑。对人类来说,多种工具可选有时很方便;但对智能体来说,冗余会增加选择歧义。因此他们收敛并合并了一些工具调用。
第二,Guide the Goal, Not the Path。过度规定提示词会降低效果。许多分析问题看似结构相似,但细节差异足够大,僵硬指令会把智能体推向错误路径。更好的方式是给高层目标,让模型自己选择合适执行路线。
第三,Meaning Lives in Code。Schema 和历史查询只能描述表的形状与用法,真正的业务含义往往藏在生成这张表的代码里。pipeline 逻辑包含假设、freshness 保证和业务意图,而这些通常不会出现在 SQL 或 metadata 中。通过 Codex 读取代码库,智能体能更准确回答“这张表里有什么”和“什么时候可以用它”。
同一个愿景,新的工具
OpenAI 计划继续提升这个智能体处理模糊问题的能力,加强可靠性和验证,并把它更深入地接入日常 workflow。它的理想形态不是一个额外工具,而是自然融入员工已经工作的地方。
底层模型推理、验证和自我修正能力会继续进步,但团队使命保持不变:在 OpenAI 的数据生态中,稳定、快速、可信地交付数据分析。